
Starting Point
Before we can discuss enabling and scaling the delivery of machine learning, we must understand the full scope of the machine learning process. While much of the industry dialogue around machine learning continues to be focused on modeling, the reality is that modeling is a small part of the process. This was poignantly illustrated in a 2015 paper by D. Sculley, et al, “Hidden Technical Debt in Machine Learning Systems,” Advances in Neural Information Processing Systems, and remains true today.
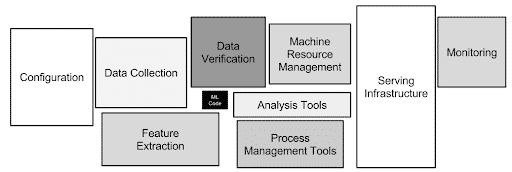
In order for organizations to reap the rewards of their machine learning efforts and achieve any level of scale and efficiency, models must be developed within a repeatable process that accounts for the critical activities that precede and follow model development.
When presented with a new problem to solve, data scientists will develop and run a series of experiments that take available data as input and aim to produce an acceptable model as output. Figure x presents a high-level view of the end-to-end ML workflow, representing the three major “steps” in the process—data acquisition and preparation, experiment management and model development, and model deployment and performance monitoring—as well as the iterative loops that connect them.

Data Acquisition and Preparation
To build high quality models, data scientists and machine learning engineers must have access to large quantities of high-quality training data. This data very rarely exists in a single place or in a form directly usable by data scientists. Rather, in the vast majority of cases, the training dataset must be built by data scientists, data engineers, machine learning engineers, and business domain experts working together.
In the real world, the creation of training datasets usually involves combining data from multiple sources. For example, a data scientist building a product recommendation model might build the training dataset by joining data from web activity logs, search history, mobile interactions, product catalogs, and transactional systems.
Once the data has been acquired, it is common to do some data visualization and exploration (often referred to as Exploratory Data Analysis). In this step, the data scientist can look at the types and volumes of data, do some initial statistical analysis, and look for human-visible patterns to determine if it could be useful for training a model.
Once the data has been selected, sourced, and understood, it must be prepared for model development. To do this, data scientists will apply a series of actions to the raw data to cleanse and normalize it. Examples include removing corrupt records, filling in missing values, and correcting inconsistencies like differing representations for states or countries.
Transformations may also be required to break up data into multiple fields, or combine it or even join it with data from other tables. All of this is in preparation for eventual Feature Engineering and Extraction.
As the data is cleansed and transformed, data transformation rules are generally captured and if your systems are complete, the datasets created can also be versioned. With a Data Pipeline tool, the team should be able to store, name, and reuse all of the data transformations on future projects as well as provide “Data Lineage” or a record of where the data came from and what happened to it along the way.
In some cases, the data will need to be labeled. Particularly in deep learning, where there is a lot of unstructured training data, there may be a need for extensive data labeling. For example, if an autonomous vehicle is being trained to recognize stop signs hidden behind branches, humans and simulators are used to label millions of partially obscured stop signs so that the neural network will have a higher chance of successfully interpreting future images as stop signs, so that it can take the correct action. Data labeling services (and simulators that pre-label elements in the simulation) have been growing quickly to address this problem.
As a result of the organizational and technical complexity involved, the process of acquiring and preparing enterprise data can consume the vast majority of a data scientist’s effort on a given project—50 to 80 percent, according to some reports.
If not accounted for during planning or supported by appropriate processes and tools, data acquisition and preparation can consume all of the time and resources allocated for a project, leaving little available for the remaining steps in the machine learning process.
Model Development and Training
Next we have Feature Engineering – the iterative process of creating the features and labels needed to train the model. Simple examples of feature engineering include generating derived features (such as calculating an age from a birthdate) or converting categorical variables into binary variables (such as converting gender (“female”) into two columns (“male” = 0 and “female” =1). This is known as one-hot encoding.
Feature engineering is often performed in lockstep with model training, because the ability to identify helpful features can have a significant impact on the overall success of the modeling effort.
Identifying and creating the right set of features can be very time-consuming. Once those features have been created and it has been determined that they are the best for a given model, they should ideally be made available to other team members for training other models by putting them into a Feature Store – a database of features that can be named, shared, and reused.
Because training is often done in batch mode and production inference (predictions) are usually done in real-time/streaming environments, if there IS a feature store in place, home-built or not, quite often a team will end up building two versions – one optimized for batch storage access and one for real-time operations – this is a recipe for complexity. There are solutions emerging to address both the batch and real-time aspect with a common underlying data store so that features can be used throughout the model development lifecycle without having to store them in multiple locations that will likely go out of sync over time.
For an organization to be able to predictably produce AI and ML models, it needs to build a production system that lets them build ML pipelines and workflows. These are more comprehensive than data pipelines (see above) and encompass a complete set of actions and artifacts that span the ML process from data acquisition and preparation, through development and training, and into production and ongoing operations. The key is to ensure that all process flows and artifacts are saved, named, shared, documented and able to be reused.
Because model development is a rapidly evolving field and the frameworks, languages, and tools are improving rapidly, an organization’s ML system should support a broad set of developer tools from notebooks to other integrated development environments so that people can work the way they want to achieve the team goals.
Experimentation is central to the machine learning process. During modeling, data scientists and machine learning engineers (MLEs) run a series of experiments to identify a robust predictive model. Typically, many models—possibly hundreds or even thousands—will be trained and evaluated in order to identify the techniques, architectures, learning algorithms, and parameters that work best for a particular problem. Because this is such an interative process, it makes sense to have a way to document, save, audit, and even re-run experiments at a later date. This is what experiment management tools do.
In addition, a variety of tools under the broad banner of “AutoML” are finding popular use to automate aspects of feature engineering, model selection, and even hyperparameter tuning and optimization. These systems can create and test a wide variety of feature combinations as well as models, in order to find the best combinations and do so much faster than human teams can do it.
Model deployment
Once a model has been developed, it must be deployed in order to be used. While deployed models can take many forms, typically the model is embedded directly into application code or put behind an API of some sort. HTTP-based (i.e. REST or gRPC) APIs are increasingly used so that developers can access model predictions as microservices.
While model training might require large bursts of computing hardware over the course of several hours, days or weeks, model inference—making queries against models—can be even more computationally expensive than training over time. Each inference against a deployed model requires a small but significant amount of computing power.* Unlike the demands of training, the computational burden of inference scales with the number of inferences made and continues for as long as the model is in production.
Meeting the requirements of inference at scale is a classic systems engineering problem. Addressing issues like scalability, availability, latency, and cost are typically primary concerns. When mobile or edge deployment is required, additional considerations like processing cycles, memory, size, weight, and power consumption come into play.
At a certain point, we often end up needing to turn to distributed systems to meet our scalability or performance goals. This of course brings along its own set of challenges and operational considerations. How do we get our model onto multiple machines and ensure consistency over time. How do we update to new models without taking our applications out of service? What happens when problems arise during an upgrade? How can we test new models on live traffic?
Fortunately for those deploying models, much progress has been made addressing these questions for microservices and other software systems.
Model monitoring
Once a model is put into production, it is important to monitor its ongoing performance. Machine learning models are perishable, meaning that the statistical distribution of the data a model sees in production will inevitably start to drift away from that seen during training. This will cause model performance to degrade, which can result in negative business outcomes such as lost sales or undetected fraudulent activity if not detected and addressed.
Production models should be instrumented so that the inputs to and results of each inference are logged, allowing usage to be reviewed and performance to be monitored on an ongoing basis. Owners of models experiencing degraded performance can use this information to take corrective action, such as retraining or re-tuning the model.
Business or regulatory requirements may impose additional requirements dictating the form or function of model monitoring for audit or compliance purposes, including in some cases the ability to explain model decisions.
In our next article in this series, we will talk about Machine Learning Platforms and why they’re important.





