
Long before starting the TWIML podcast, I worked at the intersection of the two technology shifts that ultimately enabled modern artificial intelligence: cloud computing and big data. AWS was the clear leader in cloud even back then, so I jumped at the opportunity to attend the company’s first re:Invent conference way back in 2012.
“Hustled” may be a more accurate description. I remember showing up in Vegas with no pass to the event and a super cheap room at Ceasar’s Palace, determined to find my way into the event. Ultimately I was able to get registered, and I had a great time learning and connecting at the company’s inaugural user conference. Since then, I’ve attended re:Invent most years prior to the pandemic, and it remains one of my favorite vendor conferences even as it’s expanded from about 5,000 attendees to over 30,000.
This year, like most in recent history, AWS announced a slew of new ML/AI services and features at re:Invent across all layers of the stack: from high-level AI services, to tools for data scientists and ML engineers under the SageMaker umbrella, to new ML-tuned hardware and infrastructure options.
Here are a few of the announcements I found most interesting, and my take on each:
Amazon SageMaker Canvas
Amazon SageMaker Canvas is a new no-code model creation environment that aims to make machine learning more accessible to business analysts and other non-data-scientists. Canvas allows these users to build ML models from tabular datasets that they upload (e.g. as CSV files). Currently regression, time series forecasting, and classification are supported. Behind the scenes, Canvas uses AWS’ Autopilot service to build the model. A simple analysis console allows users to explore model characteristics like performance and feature importance. Models created with Canvas can be exported to SageMaker Studio, allowing data scientists to dig into their configuration using more full-featured tools.
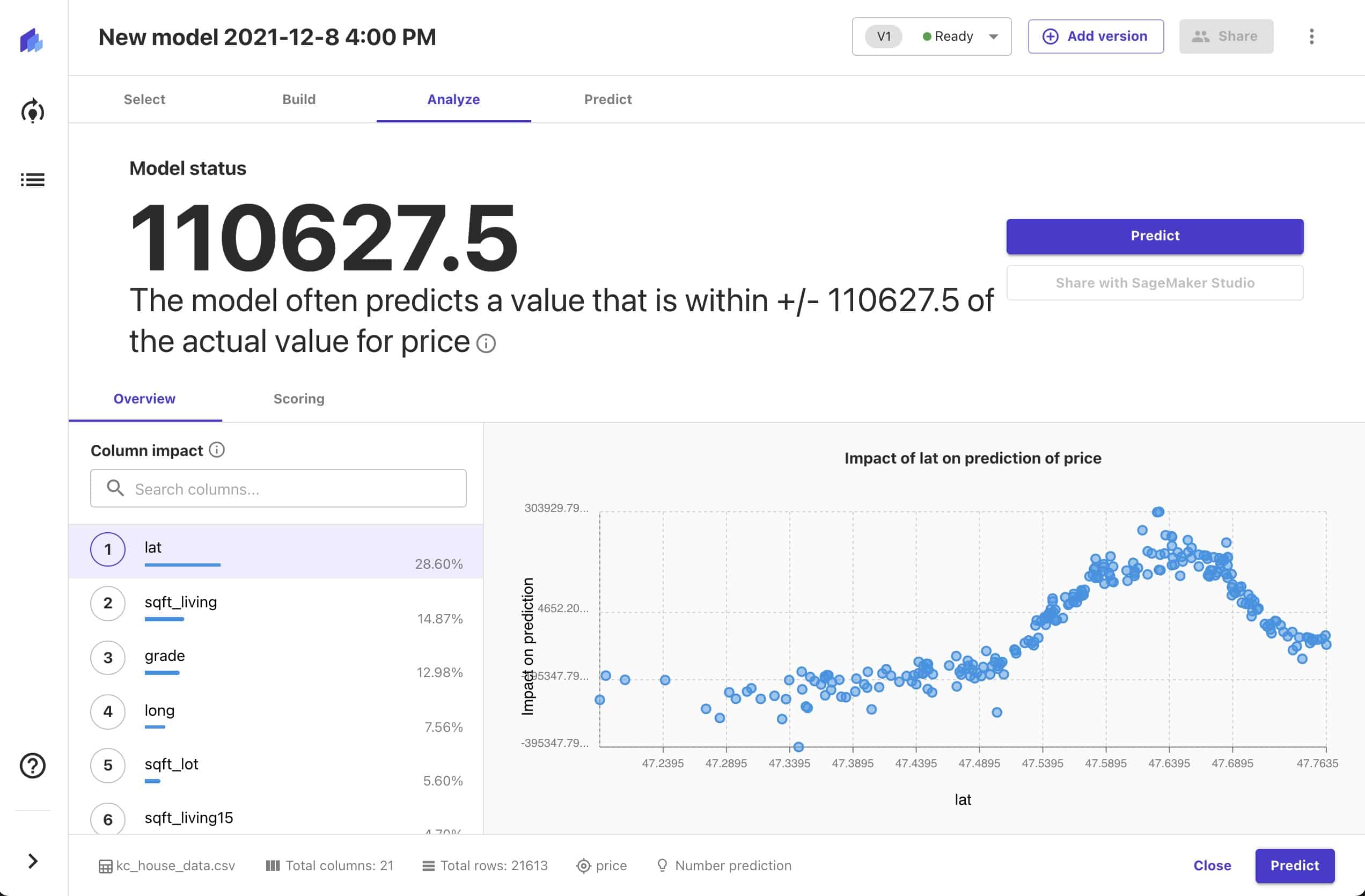
TWIML Take: In its current state, Canvas is a very rudimentary tool, especially compared to more mature contemporaries like DataRobot and H2O. I’m not sure it offers enough knobs or transparency to be practically useful, even for the business analyst, but as we well know, AWS likes to plant the flag in an area they think is interesting, then rapidly build out new capabilities and features over time. It will be interesting to see how quickly and in what direction Canvas evolves.
More broadly, while I appreciate the step towards “democratization” that Canvas embodies, I am concerned by the potential danger of putting opaque predictive models into the hands of users that may not fully understand their workings or implications. In general I think we need to see much greater investments in education and guardrails to complement the broader availability of tools targeting “citizen data scientists.”
SageMaker Studio Lab
SageMaker Studio Lab is a free, hosted Jupyter Notebook service aimed at ML beginners and enthusiasts. Studio Lab is the AWS response to Google Colab, and the offer is similar — free Jupyter Notebook environments with up to 12 hours of CPU runtime, 4 hours of GPU runtime, and 15GB of storage. Studio Lab does everything you’d expect a Notebook offering to do and includes native integration with git and GitHub and support for JupyterLab extensions.
TWIML Take: While it’s not too painful to get Jupyter Notebook running on your laptop, offerings like Studio Lab that offer free GPU are a gamechanger for those learning ML and deep learning. While the stated 4 hours of GPU runtime is less than the 12 hour maximum offered by Google Colab, Google’s actual limits are dynamic and can be unpredictable, and often require users to wait a long time between sessions. I’m told by the AWS team that with Studio Lab, once your 4 hours is up, you can just restart your runtime and start over.
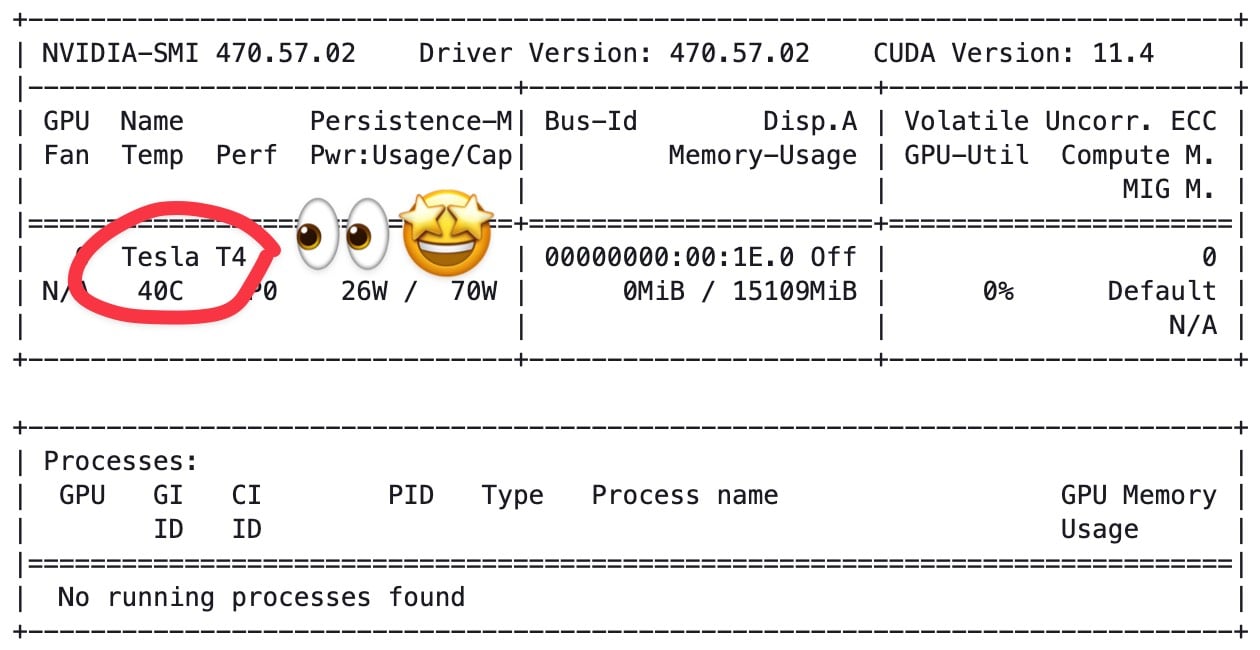
A more clear advantage of Studio Lab for GPU users is its more modern hardware. My Studio Lab instance has a T4 GPU, while Colab users get K80 GPUs. The former are two generations newer and provide 33% more RAM. Depending on your project, this can amount to a significant performance increase.
Also interesting is that the onboarding experience won’t require a regular AWS account and as a result is much smoother for new users, avoiding the inevitable confusion that the AWS console and ecosystem can present for the uninitiated.
SageMaker Ground Truth Plus
SageMaker Ground Truth Plus adds domain and industry-specific expert labeling to the existing Ground Truth service. Ground Truth was originally launched three years ago to make it easier for users to label data using unskilled Mechanical Turkers. In addition, it provides a multistep labeling workflow that incorporates ML models for pre-labeling and machine validation to reduce labeling cost and improve data quality.
TWIML Take: By adding expert labeling to its repertoire, SageMaker Ground Truth Plus becomes more competitive with data labeling firms such as Appen, Scale, Innodata and others. Similarly, the incorporation of ML-based pre-labeling and validation workflows start to close the gaps between Ground Truth and the “intelligent labeling” capabilities of those same vendors as well as specialists like Snorkel and Alectio. (Stay tuned for deep Solutions Guide coverage of Data Labeling and Annotation, coming soon!)
Ultimately, the types of engagements contemplated by Ground Truth Plus look much more like professional services engagements than the commoditized crowdsourced labeling offered with Ground Truth. Indeed, the first step in the GTP process is to submit a request to an AWS Expert who will set up a call to discuss your project. This isn’t the typical MO of AWS and it remains to be seen if and how they will scale it.
SageMaker Training Compiler
SageMaker Training Compiler is a new compiler that optimizes deep learning models for training on particular computing hardware—specifically SageMaker GPUs—resulting in faster and cheaper training. Under the covers, SageMaker Training Compiler extends the open source XLA compiler, a Tensorflow project with support for Pytorch, JAX and other ML frameworks. Using graph-level optimization, data flow-level optimizations, and various back-end optimizations, the company reports overall acceleration of up to 50%. A specific example cited was a fine-tuning task for Hugging Face’s GPT-2 model in which the Training Compiler reduced training time from nearly 3 hours to 90 minutes.
TWIML Take: With the explosion of interest in very large deep learning models such as Transformer-based large language models (LLMs) with hundreds of billions or trillions of parameters, anything that can be done to reduce training time becomes extremely important in helping model builders iterate more quickly, reducing the cost of training, and reducing their environmental impact. If this can be used with existing hardware and without significant code changes, all the better.
AWS isn’t alone in their interest in compilation. OctoML is an example of a vendor offering a platform-agnostic ML compiler—in fact, the focus of their business is commercializing TVM, the open source project that AWS’ Neo inference compiler is based on. But, it makes sense for compilation to be built into the platform as well. Ultimately AWS’ goal with compilation is to raise the level of abstraction away from individual hardware choices (such as GPU dependencies) to give them greater flexibility, and allow developers to focus on what they care most about—the computational graph.
SageMaker Serverless Inference
SageMaker Serverless Inference is a new inference option for SageMaker that allows developers to deploy models using AWS’ serverless compute infrastructure. Serverless Inference targets intermittent inference workloads that can tolerate the relatively longer startup times, overhead and limitations of the AWS Lamda infrastructure. (SageMaker offers three other inference services targeting real-time, batch, and asynchronous workloads.)
TWIML Take: SageMaker Serverless Inference is the productization and refinement of something that folks have been doing on AWS for a while now—using Lambda and related AWS serverless services to deploy ML models for inference. In doing so, SageMaker Serverless Inference promises a more productive and tightly integrated user experience.
The FAQ here is whether Serverless Inference allows users to sidestep the historical limitations of Lambda functions, and the answer is unfortunately no. As noted above, Serverless Inference is based on the underlying Lambda technology, so it inherits all of its limitations. That said, my contacts at AWS point out that the limitations of Lambda, such as on model size, have been relaxed over time and are not as constraining now as they once were. Still, while Serverless Inference supports models of up to 6GB memory size, customers still typically choose to run large deep learning models on provisioned endpoints because they can load much larger models and take advantage of AWS’ various acceleration options.
Separately, and testifying to the complexity of getting inference right in the cloud, AWS also announced Inference Recommender, a service that uses machine learning to help address the challenge of identifying the best instance types for inference workloads.
Conclusion
These re:Invent announcements center on three AWS priorities for its ML/AI services this year:
- Drive greater access to machine learning through new tools like Canvas and Studio Lab, and new initiatives like their courses and AI & ML Scholarship Program
- Build on its data acquisition and labeling capabilities with Ground Truth Plus and support for a broader set of data engineering tools through SageMaker notebooks
- Enable the industrialization of ML in the enterprise through faster training (Training Compiler and new instance types) and new inference options (Serverless Inference)
In parallel to the release of new tools for ML/AI builders, we also continue to see AWS build machine learning more deeply into new and existing products and generally take advantage of it to make their infrastructure offerings more intelligent.
The pace of innovation at AWS continues to impress and it will be interesting to see how these services evolve and compete over time.





