
(NOTE: The content in this post has been repurposed from our e-book titled The Definitive Guide to Machine Learning Platforms. It was accurate at the time of writing – way back in 2019. As we launch the Solution Guide, we have just finished hosting this year’s TWIMLcon conference and we got to look under the covers of a number of new in-house ML platforms. If you’re interested in seeing some of those designs, then head over to https://twimlcon.com/ondemand/ and you can sign up for an On Demand Pass.)
In this post, we present three representative ML platforms: Airbnb’s Bighead, Facebook’s FBLearner, and LinkedIn’s Pro-ML. Each of these platforms was developed in response to the unique situation, challenges, and considerations faced by its creator. As we will see, each platform took on a unique form as a result of these influences, while at the same time many common patterns are evident.
Airbnb’s Bighead
Machine learning has long been used to power Airbnb’s core accommodations marketplace with applications like search ranking, smart pricing, and fraud prevention. In 2016, only a few major ML models were in production and it typically took teams eight to twelve weeks to build new models. The Airbnb machine learning technology stack at the time was based on Spark, Scala, and a homegrown machine learning library called Aerosolve.
In 2016, the company’s engineering team realized that in order to meet its business goals, it would need to dramatically increase the velocity with which it was putting machine learning models into production. There was a growing desire on the part of Airbnb’s development teams to take advantage of rapidly evolving third party ML tools like TensorFlow, PyTorch, and SciKit Learn. They also experienced frustrating discrepancies between the results they were seeing in offline training and online serving, preventing them from meeting desired performance objectives and eroding confidence in their machine learning models.
To address these issues, Airbnb established an ML infrastructure team in 2017. The team describes its mission as eliminating the incidental complexity of machine learning—getting access to data, setting up servers, and scaling model training and inference, allowing developers and data scientists to focus on dealing with its intrinsic complexity—identifying the right model, selecting the right features, and tuning model performance. In establishing this team, they empowered more users to build ML products, reduced the time and effort required to do so, and produced more consistent results with the models they put into production.
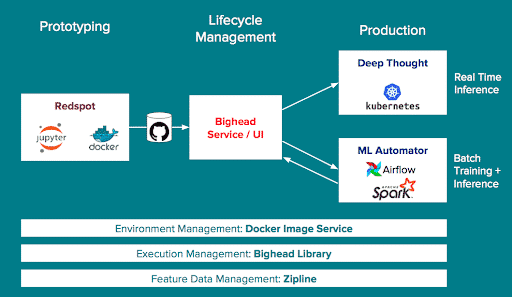
Airbnb’s internal ML platform is called Bighead. Bighead is an end-to-end platform for building and deploying ML models that aims to make the machine learning process at Airbnb seamless, versatile, consistent, and scalable. It was built in Python and relies on open source technology like Docker, Jupyter, Spark, Kubernetes, and more. These open source components are customized and integrated for Airbnb’s specific needs. Like much of Airbnb’s technology infrastructure, Bighead runs on Amazon Web Services.
Bighead consists of the following major components:
Zipline
Zipline is a feature store that sits in front of Airbnb’s data warehouse. Apache Spark powers many of its features, especially those performing offline tasks such as training set backfills and feature computation. Zipline allows Airbnb’s ML to more easily and consistently access feature data for ML models. It provides:
- A feature repository providing vetted crowdsourced features at different levels of granularity such as host, guest, listing, or marketplace
- An easy-to-use configuration language for defining new features
- Efficient point-in-time data backfills
- Feature exploration and visualizations
- Automatic data quality monitoring
- Consistency between feature availability for offline training and online scoring (batch and streaming)
- Explicit ownership of feature data pipelines
Airbnb has reported that Zipline has reduced the time that its ML practitioners spend collecting data and writing transformations for machine learning tasks from months to days.
Bighead Library
Bighead Library is the core execution management and data transformation library in Bighead. It allows users to define machine learning workflows for data preprocessing, training, inference, model evaluation, and visualization in a standard graph-based (i.e., directed acyclic graph, or DAG) format. Bighead Library pipelines are reusable, composable, and shareable.
A variety of popular machine learning frameworks are supported in Bighead Library pipelines including TensorFlow, PyTorch, Keras, MXNet, Scikit-learn, XGBoost, H2O, R, and more. In addition, Bighead Library provides a catalog of over 100 different canned transformations that can be applied to data in a variety of standard formats such as text or images, encouraging users not to “reinvent the wheel.”
Pipelines built with Bighead Library propagate feature metadata end-to-end so that users can understand feature provenance and visualize feature importance at the end of their pipelines.
Redspot
Redspot is a centrally managed, multi-tenant Jupyter Notebook service available to Airbnb’s machine learning practitioners. It is a fork of the official JupyterHub project that is tightly integrated with the rest of the Bighead ecosystem.
Redspot lets Airbnb’s ML practitioners use notebooks as first-class tools by providing easy access to data and pipelines, and allowing them to deploy notebooks all the way to production.
Every user’s environment in Redspot is containerized via Docker containers. This allows them to install systems or Python packages without affecting other users. Users can use vetted base images from Airbnb’s in-house image repository or create new images using provided build tools.
Redspot notebooks are version controlled, can be reverted to prior checkpoints, and can be easily spawned on dedicated AWS CPU and GPU instances. Notebooks and files are easily shared via AWS EFS.
Bighead Service
Bighead Service establishes the core modeling framework for Bighead and provides centralized model lifecycle management and experiment management services. It provides a single source of truth and history for models at Airbnb, whether they’re in development on a developer laptop, or running in a production cluster.
Bighead Service keeps track of “Model Versions” consisting of the model’s code and a Docker image through which it can be run, and “Model Artifacts” consisting of a set of model parameters such as those learned via training. Instantiated Bighead models can be accessed via a lightweight standardized API baked into the various Docker images.
Bighead Service also provides a user interface for:
- Experimentation. Users can set up and track online model experiments.
- Evaluation. Users can access a dashboard of model metrics, visualizations, and alerts.
- Deployment. Users can track model changes, and deploy and roll back models.
Deep Thought
Deep Thought is a scalable serving environment for Bighead models. It is based on containers and Kubernetes, providing consistent development and training environments, runtime isolation, and scalability. It is completely configuration-driven so data scientists don’t need to involve engineers to deploy new models.
Deep Thought exposes deployed models via APIs, and provides standardized logging and alerting accessed through Bighead Service dashboards. Models have access to feature data from Zipline.
ML Automator
ML Automator is a workflow engine that runs behind the scenes to automate common offline tasks in Bighead such as periodic model (re)training and evaluation, batch scoring, uploading scores, and creating dashboards and alerts based on scores.
ML Automator users specify these tasks declaratively and ML Automator generates Airflow DAGs under the covers, specifying the appropriate connections to Bighead resources and Zipline data. Computation is run on Spark for scalability.
Facebook’s FBLearner
Machine learning is at the heart of many Facebook services including the newsfeed, ads, search, translation, speech recognition, and content understanding. The ubiquity of machine learning at the company is due in large part to a 2014 initiative that sought to re-envision its machine learning development process from scratch with the goal of putting state-of-the-art ML and AI algorithms in the hands of every engineer.
By mid-2016, the organization unveiled FBLearner Flow, what we now understand to be the first (and central) element of its broader ML-as-a-Service platform. FBLearner was designed with the guiding principles of reusability, scalability, and ease-of-use. At the time of its announcement, FBLearner had already had a profound impact at Facebook with approximately 150 authors creating and publishing machine learning workflows. These workflows were used by over a quarter of the engineering team and generated over 6 million predictions per second. Today, most machine learning pipelines at Facebook are run via FBLearner.
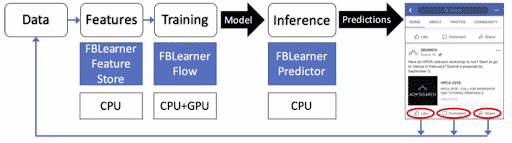
FBLearner consists of three key components:
FBLearner Feature Store
FBLearner Feature Store is the component of the FBLearner platform that allows developers to discover and use pre-built features in their models.
Feature Store is essentially a catalog, or marketplace, of feature generators for use in both training and serving scenarios. Teams at Facebook can share, discover, and consume these features to accelerate the development of their models.
The feature generators offered in Feature Store expose data in the Facebook data warehouse in a consistent manner. Feature Store provides a rich type-system for describing this data, ultimately enabling many of the downstream features of FBLearner Flow.
FBLearner Flow
FBLearner Flow is Facebook’s platform for building, training, and evaluating machine learning models. It is organized around three central concepts:
- Workflows. A workflow is a single pipeline defined within the FBLearner Flow system. Workflows describe the steps necessary to train or evaluate a specific model in FBLearner. The platform itself is agnostic to the type of ML algorithms used. Any engineer can write a workflow for their favorite algorithm and publish it to the entire team.
- Operators. Operators are the basic components from which workflows are composed. They are the smallest unit of execution in FBLearner. They have distinct inputs and outputs and run on a single machine. Operators are designed to be a very flexible abstraction. Generally, they are functions in a Python program, but essentially anything for which a binary can be provided can be turned into an operator.
- Channels. Channels represent the flow of data between operators within a workflow. They are characterized by their inputs and outputs and must have a well-defined type.
These concepts are implemented via three core components:
- A workflow authoring and execution environment. Workflows are defined in Python code with special, platform-specific extensions. Using these extensions, developers define graphs of operators and specify these operator’s parameters such as inputs, outputs, models, and evaluation metrics. Each operator declares its CPU, GPU, and memory requirements. At runtime, the number and type of input data are validated, workflows are parallelized for scalability, and they are scheduled to run on a slice of a machine that meets the requirements.
- An experimentation management dashboard. FBLearner Flow provides a user interface for launching and managing workflows and experiments, viewing and comparing experiment results, and deploying models to production. The metadata and results of all workflow runs are stored and indexed, allowing engineers to easily find experiments via any number of parameters. The system supports complex hyperparameter sweeps for model tuning and provides visualizations to help developers determine the configurations that produced the best results.
- Predefined pipelines. Flow provides a library of user-contributed machine learning workflows as well as a set of scalable workflows maintained by the company’s AI Infrastructure team. The workflows can be applied to commonly used models like deep neural networks, gradient-boosted decision trees, support vector machines, and logistic regression.
FBLearner Predictor
After training, finalized models from FBLearner Flow are then deployed to production via FBLearner Predictor. Predictor provides a scalable, low-latency, multi-tenant model serving environment for online predictions based on live traffic.
Using the integration between the Flow UI and Predictor’s model serving capability, users can run experiments in which multiple versions of live production models are deployed and compared.
Related work
Facebook’s ML platform engineering team has developed offerings for each layer of its machine learning stack. At the hardware level beneath FBLearner, they have created custom server designs (which they have open sourced via the Open Computing Project). At the framework level above FBLearner, they lead the development of PyTorch and are a leading contributor to the ONNX ecosystem for framework interoperability.
At the FBLearner level, Facebook has published only high-level descriptions of the system and its capabilities. Because of Facebook’s immense scale and unique internal systems it is unclear how much of FBLearner would generalize to third parties. Despite this, the broader ideas behind it continue to influence other systems and have certainly informed the other platforms and tools described in this ebook.
LinkedIn Pro-ML
Machine learning is in wide use at LinkedIn, powering everything from user-facing personalized news feeds and job recommendations to back-office functions such as advertising and sales lead generation (see TWIMLTalk 224, 236, 256 for more information.) In order to empower LinkedIn’s disparate teams to use machine learning more efficiently and productively, the company established a platform engineering team whose primary product today is an internal machine learning platform: LinkedIn Pro-ML.
Pro-ML is the latest step in LinkedIn’s ML platform journey. As their platform team has developed and expanded, they have successively standardized and outgrown a number of platform technologies. Initially, LinkedIn began with a Hadoop-based platform, then moved to Apache Spark and MLlib. Later, they developed and open sourced their own MLlib replacement: Photon-ML.
In parallel with LinkedIn’s evolving technology stack, the platform team’s audience has also changed. The team initially catered to the company’s core set machine learning developers. However, as in-house efforts such as its AI Academy broadened the base of developers working with AI and ML, LinkedIn’s platform team stepped up to support the needs of this broader audience.
Pro-ML is a suite of complementary systems that help streamline the model development lifecycle at LinkedIn.
Pro-ML consists of:
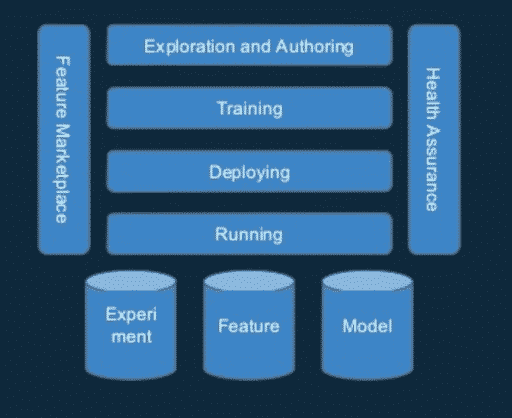
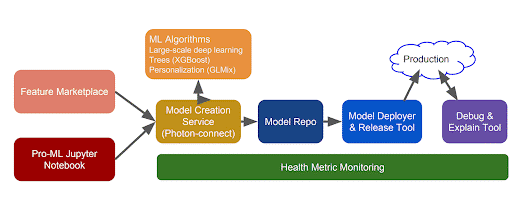
Feature Marketplace
LinkedIn observed that many of their teams were developing similar features, creating a “pipeline jungle” that was too complex to build upon. The Feature Marketplace was developed to address this challenge, providing a way for teams to simplify and unify the features available on Pro-ML. Feature providers can publish their features using simple configuration files that allow them to specify the location of their source data, such as an HDFS path or a pointer to a key-value store, along with the requisite extraction logic. The logic that provides the feature is hidden behind an abstraction layer, allowing consumers to utilize features simply by name.
Exploration and Authoring
Pro-ML provides a standardized suite of tools for model development (such as Jupyter Notebook) along with a pre-built set of ML models that developers can use off-the-shelf. Developers can specify how their models are to be trained on features from the Marketplace, as well as on custom features, using a DAG specified in code.
Training
Models in Pro-ML can be built using Tensorflow or LinkedIn’s own Photon ML. Photon ML is an open source ML library that their algorithms team developed for Spark. It offers many models in popular use at LinkedIn such as Generalized Linear Models and Generalized Linear Mixed Models.
Hadoop and Apache Spark provide the foundation for training models at LinkedIn with the former supplying distributed storage (via HDFS), and the latter providing the runtime platform for large-scale training and inference. LinkedIn developed and open sourced TonY (Tensorflow on YARN ) which helps effectively manage clusters running distributed TensorFlow.
Deploying
LinkedIn’s production models can be very large and often need to be distributed over multiple machines to perform adequately. LinkedIn has developed workflows and tooling that ensure new models can be deployed and released into production in a consistent and controllable way. This provides developers with a standardized way of deploying and monitoring their models while ensuring a high quality of service for production systems.
A web interface called Model Explorer allows users to discover, publish, and deploy models into production. It also provides the ability to perform model validation in a test environment. Once validated, models can be deployed to a single instance. Once validated on a single instance, the model can then be scaled to many production instances.
Health Assurance
]Pro-ML continuously monitors feature distributions to detect changes. Monitoring includes mean, variance, and some higher-order statistics. If the feature distribution exhibits unexpected behavior, the system automatically generates alerts. When an alert is received, the explanation of why the model misbehaved can be investigated.
All of these platforms share a common base architecture
As we examine all of these early leading edge machine learning platforms built by leaders in the internet and web space, we find a lot of common architectural elements. These systems are generally end-to-end, providing a full view of the machine learning process from original data evaluation all the way through to production and monitoring. Some of the common patterns include:
- Data access and preparation tools that help with accessing data from various locations; analyzing that data for fit with the task at hand; data cleansing; and data transformation (ETL/ELT);
- Tools for feature development, model development, experiment management, and model tuning;
- Tools for moving from pre-production to production and monitoring the models once they are in production;
- System-wide functions such as a foundation of permission-based sharing of assets, data, and models; integration with Docker and Kubernetes for container orchestration; monitoring; security; and more.
In the next post in this series, we’ll be covering how to develop your own Machine Learning Platform Strategy.





