
Introduction
In spite of all the hype, the reality is that you don’t need to do anything different for your company to benefit from AI. You don’t need to hire data scientists, collect training data, or build machine learning or deep learning models.
It is already the case, and it will be increasingly true in the future, that AI technologies will power many of the products and services that your enterprise uses. Your enterprise will be a passive beneficiary of AI.
These passive benefits, however, are a rising tide that floats every boat. Your enterprise gets only what is available to everyone else in the marketplace. In other words, they won’t help your enterprise gain a competitive advantage among its peers. So, the question becomes: what will help your enterprise gain a competitive advantage?
Competing on Models
Achieving competitive advantage with AI requires a much more active approach. It is done by applying your enterprise’s proprietary data to solve your enterprise’s proprietary business problems through the creation of proprietary models. The benefits of such an approach can be significant.
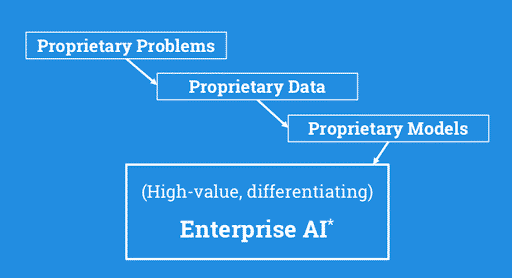
In a 2016 paper on The Netflix Recommender System, authors Neil Hunt (former chief product officer) and Carlos Gomez-Uribe (former VP of product innovation), reported: “over years of development of personalization and recommendations, we have reduced churn by several percentage points. Reduction of monthly churn both increases the lifetime value of an existing subscriber, and reduces the number of new subscribers we need to acquire to replace canceled members.” The authors estimated that “the combined effect of personalization and recommendations save[d Netflix] more than $1B per year.”
Another example of the advantage gained through proprietary models comes from a 2018 TWIML interview with Jeff Dean, the head of Google AI. In explaining the impact of the company’s investment in machine learning models, Jeff cited the replacement of the complex, decades-old, phrase-based translation system used to power Google Translate with a system based on deep learning. Not only is the resulting system much simpler—a system of around 500,000 lines of code was replaced with around 500 lines of TensorFlow code—but the performance gains in making this change exceeded the performance gains of the previous decades of work on the legacy system.
With examples like these, it’s no surprise that enterprises across a wide variety of industries are investing significantly in machine learning.
Enter the Model-Driven Enterprise
Enterprise AI represents a fundamental shift in both the technology and business landscapes, with an impact as significant as that of software itself.
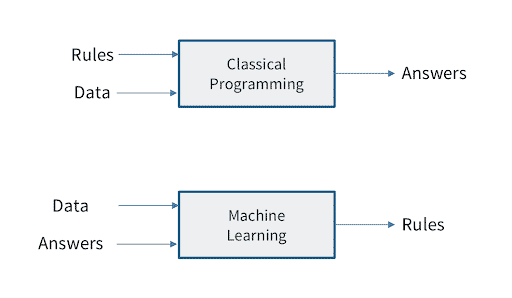
Consider the impact traditional software has had over the past 30 years. Can you imagine an enterprise of any significance not depending on a huge amount of software? Now consider that Enterprise AI is at the dawn of a new age of software—“Software 2.0” as described by Andrej Karpathy, Director of AI at Tesla.
Software 2.0 refers to the idea that machine learning (i.e., Software 2.0) allows us to extract the rules for solving some problem in our business automatically from data we’ve collected about the problem. In other words, the modeling process automates the creation of software for us. This can occur in situations in which it would be very difficult for humans to identify, much less program, the complete set of rules that govern the solution to a particular problem.
The widespread adoption of Enterprise AI will have broad implications for businesses; so much so that we believe it will define a new wave of business productivity marked by what we call the Model-Driven Enterprise.
Consider again the role of software in the enterprise, and a few of the major technological and productivity shifts that it has enabled over the past 30 years.
- The process-driven 90s. The 90s saw the rise of the process-driven enterprise. During this period of time—which was marked by the widespread application of ideas like Six Sigma, Lean, and business process reengineering—enterprises reorganized themselves around their core processes, collected data about the execution of these processes, and used reports about this data to analyze and improve their performance. ERP systems and business intelligence (BI) tools were among the major enterprise technologies that supported this shift. The connection between data collection and process improvement was a highly manual one, with humans reviewing reports on a relatively infrequent basis (quarterly or monthly reporting cadences were not uncommon), applying fixed rules and intuition, and using the information gained to drive behavior changes.
- The data-driven 00s. With Y2K remediation efforts and the introduction of the euro leading to a boom in ERP deployment in the late 90s, widespread digitization of enterprise processes set the stage for a boom in the amount and quality of data collected by enterprises. At the same time, connectivity within and between enterprises became ubiquitous, and the web and mobile came into their own as channels for consumer engagement. Much of the data collected found its way into traditional enterprise data warehouses (EDWs) and eventually into alternatives like Hadoop. While improvements in software development methodologies and the introduction of frameworks like J2EE and .NET, along with the rise of tools like business process management systems (BPMS) and business rules engines, meant that more decisions could be made in software, developing these systems remained slow and risky. Humans remained central to most enterprise decision-making. “Big data” promised to decrease the time lag between insight and action, and was generally successful in getting this reduced from quarters and months down to weeks.
- The model-driven late 10s and 20s. In the current model-driven era, enterprises have the opportunity to tap into a fundamentally new source of value creation by putting all the data they’ve collected to productive use through the creation of machine learning models. These models will be deployed within a wide variety of software applications and systems. This will allow the machines that interact with customers and control back-office functions to make high-fidelity decisions instantaneously. Because these models are created by software through the training process, as opposed to via manual software development, innovation cycles are reduced to days or hours. The technology innovations supporting the shift to model-driven enterprises include deep learning frameworks like TensorFlow and PyTorch as well as a new breed of machine learning platform technologies designed to eliminate friction at various points of the model delivery process.
| Process-Driven | Data-Driven | Model-Driven | |
| Timeframe | 1990s | 2000s | Late 2010s to 20s+ |
| Use of Data | Enterprise organized around relatively static processes performed by humans | Incremental improvements; data collected at different points in processes | Data collected at each step of processes used to train next iteration of model |
| Decision-Making | Fixed rules and intuition used to make decisions | Data used by humans to make more informed, better aligned, and more timely decisions | Data used by machines to make high fidelity decisions instantaneously |
| Innovation Cycles | Months to Years | Weeks to Months | Hours to Weeks |
Figure 1. The process-driven, data-driven, and model-driven eras in business
In this light, it becomes clear that Enterprise AI is much more than a fad, but the next logical step in a 50-plus year march of enterprise technology towards supporting improved business decision-making, faster innovation cycles, and improved business performance.
Getting to Model-Driven
As models emerge as a significant source of proprietary business advantage, the ability to create and deliver them to production in an efficient, repeatable, and scalable manner becomes a critical competency.
Key Challenges
As is often the case with other emerging technologies, enterprises face people, process, and technology challenges in their endeavors to efficiently deliver machine learning models to production.
People
Enterprises face a variety of people-related challenges when implementing machine learning and AI. First is the scarcity and cost of experienced data engineers, data scientists, and machine learning engineers. Assuming the hiring hurdle is overcome, numerous organizational and cultural challenges await. Culture is a key factor in the productivity of enterprise machine learning organizations because the organization’s approach to problem definition, experimentation, priorities, collaboration, communication, and working with end-users/customers are all guided by organizational culture.
Process
Developing and deploying models is a complex, iterative process with numerous inherent complexities. Even at small scales, enterprises can find it difficult to get right. The data science and modeling process is also unique (and difficult) in that it requires a careful balance of scientific exploration and engineering precision. Space must be created to support the “science” aspect of data science, but a lack of rigor and automation gets in the way of efficiency. The key is to apply rigor and automation in the right places, and there are challenges opportunities to do so, as we will see.
Technology
Technology—and its key role in allowing an organization’s people to execute its machine learning process more efficiently—is the central focus of this Solution Guide. Technology without process is simply a tool, and while tools can be helpful, their value is incremental. Conversely, processes without technology limits the efficiency and automation necessary to scale. It is only by supporting an organization’s people—its data scientists and ML engineers in particular—with effective processes and technology, that they are empowered to efficiently apply ML models to extract value from enterprise data at scale.
In the next post, we’ll break down the basics of Machine Learning.





