
You may know Intuit as the public company (INTU) behind Quickbooks and Turbotax but thanks to $20B of recent acquisitions, they are also the new owners of the Mailchimp marketing automation company and Credit Karma – a personal finance application. The company invests heavily in machine learning and AI as a way to deliver new features and capabilities in their products, to enhance the customer experience, and to improve operational efficiencies.
In January 2021, during our last TWIMLcon, we were fortunate to hear from Ian Sebanja, a product manager, and Srivathsan Canchi, head of ML platform engineering, about how Intuit was handling cost-management internally for the cloud-based (mostly AWS) infrastructure that supports their machine learning efforts. In this talk, Ian and Srivasthan shared how they have grown ML use exponentially while only growing costs linearly. (One of our attendees, James Le, wrote up a nice blog post about that talk here and you can find the original talk in our TWIMLcon 2021 free on demand session archive here.)
In October 2021, Srivathsan came on the podcast (episode 438) and we talked about the ML feature store designed and built by the Intuit team. This tool eventually became the foundation of the Amazon SageMaker Feature Store product.
Srivasthan then very kindly made the introduction to Juhi Dhingra and Dunja Panic, product managers on the data platforms team at Intuit, who agreed to chat with us on our webcast about the two data platforms they have built for data processing: one for batch processes and one for streaming applications. They also shared their plans to unify these two platforms over time, and some lessons they learned that could be applied to other organizations. Check out the video below to watch the full conversation with Juhi and Dunja or scroll down to read our takeaways from this session.
Learning how to serve your internal customer
Intuit has over 15,000 employees running over 60,000 data processing workloads. Product managers and data engineers across the company are spending up to 35% of their time managing operationalization and infrastructure that is “under the water line”, taking away time and energy from focus on the product they are creating. So Juhi and Dunja and their team set out to build easy to use batch and streaming data processing platforms to simplify all of this for their internal customers and they started by focusing on the data engineer persona.
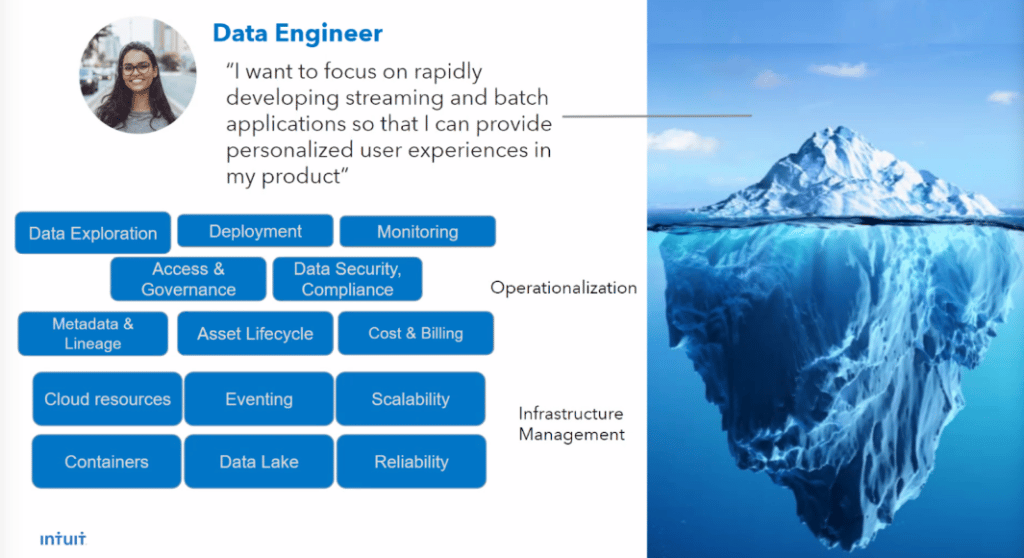
The data engineer just wants to build great end-user products and experiences. If they can focus more time on that, and less time on managing infrastructure, then Intuit and its customers will both win. To that end, they built two data processing platforms – one for batch and one for streaming – that help their internal data engineers do things in “minutes, not months.” The developer can tap into data sources like their data lake, data warehouses, and feature store, select the appropriate processor (batch or streaming), access sample code for common use cases, and provision the resulting data pipeline to production cloud infrastructure. The platform provides multi-language support and manages the orchestration, provisioning, and scale needed by the application and data processing approach chosen. It is essentially a one-stop shop that lets the user focus on the customer experience, while the platform team supports the behind-the-scenes infrastructure such as pipelines, runtimes, containers, and databases, as well as site scalability and reliability.
Streaming use case example: QB Assistant
Quickbooks has a self-help function called the QB assistant. Instead of providing canned self-help options, it is highly personalized based on the activity of the user in Quickbooks itself. By building this personalized self-help system, Intuit was able to increase user engagement, improve click-through to help docs, and reduce customer support contact rates. They did this by pulling user behavior (clickstream data) from their event store, processing it in real-time on the streaming platform, and then proposing personalized suggestions back to the user in near real-time.
Batch use case example: Cash flow forecasting
Cash flow is absolutely critical for a small business owner. In their mission to become a primary method of cash flow management for their small business customers, they built a new cashflow forecasting function into Quickbooks. To make it work, they ingest the cashflow data into the data lake, enrich it to create features using the batch processing platform, and then push those features to the feature store.
Selecting stream vs. batch processing for a given use case
We discussed how application owners make the decision between which data processing platform they should use for their application. The answers seemed to point mostly towards use case fit and budgets within the business unit.
Regarding use case fit, monthly reports, or things that only need to run periodically are good candidates for batch processing while use cases like chatbots or clickstream analytics are better candidates for streaming data processing.
With respect to budgets and running costs, batch processing is inherently cheaper. In batch processing, infrastructure can be spun up (including things like Amazon EMR) and run only for the duration of the batch job and then be turned off. Streaming applications are “always on” by their nature, so they will constantly be running some level of infrastructure to support base demand and that will generally speaking, have a higher cost than a batch processing operation.
What does the future hold for this platform?
With so much of the platform built and operational, we wondered what was next? Were there still challenges? Juhi and Dunja quickly pointed out that they were in no way done building out the platform. They addressed issues such as having too many tools for users, still having issues onboarding data, getting clean data, having good data governance, enforcing ownership and stewardship of data, and enabling trust in the data for their internal customers.
Their goal going forward is to build a completely unified “data mesh” where people can discover data products, explore them, and leverage them, or build on top of them. They want to provide a simple, well integrated, easy to use data processing experience with:
- Integrated access, discovery, exploration, model development, analytics
- One unified experience for stream and batch processing
- Low-code/no-code options for less technical personas, including helpers for debugging issues on-the-fly
- High reusability of data products by recommending aggregates and transformations of existing data products
- Built in governance, data quality, and lineage
Lessons learned in their data journey
Not every company is as mature as Intuit when it comes to their data infrastructure, systems, and practices. So we asked Juhi and Dunja to share their thoughts on some things that any company can take away from their experience and apply to their own situation and they shared a number of great principles:
- Understand YOUR business. You can use overarching design principles but your business should ultimately dictate what you do in terms of designing and building your own platform.
- Understand your own data, data lake, data warehouse, and tools (including which ones work for your users and which ones don’t).
- Keep the solutions as simple and broad-based as possible – do not deploy a tool for a single use case or solution.
- Try to serve multiple personas even if you just start with one. Intuit started with the hardest one (data engineer) and are now aiming to support other types of engineers (specifically, ML and SW engineers), as well as moving towards the less-technical personas such as data analysts and business analysts.
- Remember to balance priorities – are speed and agility more important or governance? Only you and your business know what the right answer is.
There was so much more covered in the Q&A, where we discussed feature storage for batch vs. streaming, data lineage, multi-cloud infrastructure management, and how they keep their users on the rails without breaking data schemas or standards. We invite you to listen to the entire episode here.
We want to thank Juhi and Dunja for coming on the webcast and we’ll look forward to another update soon!




