
Hey there!
This week’s main article is a bit longer than usual, but I hope you’ll find it both interesting and thought provoking.
Google’s New Cloud AutoML: What is it and broader implications
Developing machine learning systems is an inherently iterative process and one which can be, as a result, tedious, time consuming and expensive. In addition to the data science work that needs to be done, the goal of which is the development of a predictive model, there are also a host of IT issues that need to be addressed to put ML and AI models into production.

To help organizations overcome these issues, the major cloud vendors, as well as many independents, offer cloud-based prediction APIs that developers can easily integrate into their applications. The benefit of these APIs is in their ease-of-use and the fast time-to-market they enable. In most cases, developers are only minutes away from retrieving predictions using these APIs.
AI-as-a-Service Challenges
The fly in the ointment, so to speak, of these APIs has traditionally been the fact that they really only work well in fairly generic use cases. Consider the case of an object detector for photos and videos. That object detector is based on deep learning, and was trained using millions of labeled example images or video samples. But if the objects you want to identify in your videos are not well represented in the labeled data set, the neural network can’t really hope to offer accurate predictions.
 [A fly in the ointment, according to Google Cloud Vision API]
[A fly in the ointment, according to Google Cloud Vision API]
As a result, developers using AI-as-a-Service offerings face challenges relating to:
- Domain specificity. If a given service’s training dataset doesn’t span my domain, it can’t help me. For example, if I need to visually identify when toy cars are present in my images, but the training set only includes a few images containing toy cars, the service can’t really be expected to do a very good job with them.
- Fine-grained detection. What if I need to not just identify the presence of toy cars in my images, but also distinguish between different types of toy cars? Now I not only need a lot of them present in the training dataset, and need more fine grained labeling (requiring more expertise to develop by-the-way), but I also need a network architecture that is robust enough to capture the fine-grained distinctions among different types of toy cars.
- Bias avoidance. Even if our object detector has plenty of toy cars with granular labels, the performance of the detector for our application can be impacted by a variety of other factors: the distribution of the cars in the training set, the orientation of the cars in the training set, the backgrounds of the images in the training set, the lighting, quality and resolution of the images in the training set, to name a few. If any of these factors is poorly aligned with the types of images I need to analyze, my predictor is likely to underperform.
Enter Cloud AutoML
Google Cloud AutoML is a new service aimed at helping developers overcome these challenges. Cloud AutoML operates similarly to other AI-as-a-Service APIs, however, Cloud AutoML users can upload their own training datasets to augment those already collected by Google.
The first service to be released under the Cloud AutoML brand is Cloud AutoML Vision, which allows users to train custom vision models. Cloud AutoML Vision is currently in alpha release, meaning the service is in testing and access to it is limited. Interested customers must apply for access, agree to applicable terms, and have their projects cleared for use against the API.
Notable features include:
- Powered by transfer learning. We’ve talked about transfer learning a bit on the podcast (e.g. TWIML Talk # 62, 88). It’s a methodology for training a neural network on one dataset and then refining its training with another dataset. The advantage of transfer learning is that the first training, which typically uses a much larger training dataset, does much of the heavy lifting of teaching the network to make coarse-grained distinctions. This allows the second training dataset to be much smaller. In this case the first dataset is Google’s own labeled training data and the second training dataset is the customer’s. Google claims that transfer learning allows custom AutoML Vision models to achieve high domain specific performance with as few as “a few dozen photographic samples.” This is sure to be highly use case dependent.
- Automated model optimization. Cloud AutoML is powered by a number of advanced optimization techniques, like neuroevolution (discussed in detail in TT # 94), reinforcement learning (which we’ve discussed extensively, though in other contexts, such as TT # 24, 28, 43), and other automated techniques. This helps ensure that the models created by the service perform well.
- Human labeling. If you’ve got data, but it’s not labeled, Google can help you with this as part of your use of the service. It will be interesting to compare how their offering in this area compares to that of more specialized providers like MightyAI (TT # 6, 57) or CrowdFlower.
For sure, Cloud AutoML is an exciting addition to the Google Cloud Platform, and to my knowledge they’re the first major cloud vendor to announce support for customer-provided training data for cognitive APIs. This is the natural direction for these kinds of services, though, and I’d expect all major cloud vendors to announce similar capabilities within 12-18 months.
On Automated Machine Learning
While this article has already gotten fairly long for this newsletter, I wanted to comment briefly on the broader notion of automated machine learning.
Google’s clearly trying to stake some thought-leadership ground here with its naming choice for this service. I get this, and this may prove to be effective short-term positioning for them, but ultimately all users of AI-as-a-Service, particularly the less sophisticated users (from a data science perspective) that these services target, expect high levels of automation. And, as expressed above, I think the ability to bring your own training data (which kind of assumes transfer learning and automated model search/optimization) will be table stakes within a year or two.
A broader challenge posed by the AutoML name is furthering the idea that magic, black box services can get you all the way there, and that some degree of data science or statistically knowledge isn’t necessary. Google and others in this space are certainly providing a valuable service in lowering the barrier to entry for developers and enterprises interested in using machine learning, but often the issue is that without a certain degree of savvy, you don’t know what you don’t know. This is particularly true with the bias-related challenges this offering is meant to address in the first place.
Further, there are complaints that Google is attempting to hijack the term AutoML, which has existing meaning within the data science community and which has for years been the name of a workshop on the topic held at ICML and other academic conferences.
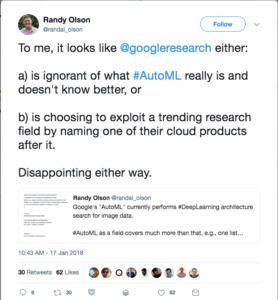
The broader field of AutoML encompasses the automation of a wide range of data science tasks, including data preprocessing, model selection, hyperparameter optimization, performance analysis and more.
Google Cloud AutoML, while powerful, doesn’t quite live up to the broader vision of AutoML: well-understood tools, algorithms and methodologies that increase the throughput and effectiveness of data scientists. This may be splitting hairs, but I do agree that the distinction between closed, black-box automation vs open and transparent tools that can be integrated into a user’s ML pipeline is an important one.
Examples of projects that have evolved out of these broader efforts include the open source auto-sklearn, AutoWEKA, and Auto Tune Models (ATM). Commercial offerings like Bonsai (TT # 43], SigOpt (TT # 50), h2o’s Driverless AI, and DataRobot also exist, falling in varying places along the transparency spectrum.
To Google’s credit, they’ve published extensively in this area and in the academic literature generally. Further, the company is certainly heavily invested in open source tools in this domain (e.g. TensorFlow). And Cloud AutoML Vision is but a first installment toward a broader vision of an automated ML platform. It wouldn’t surprise me at all to see Google Cloud AutoML technologies eventually surface as open source projects within in the TensorFlow ecosystem over time.
Finally, there’s an interesting conversation to be had about the impact of automated ML tools on the space:
- Will lowering the barrier to entry result in a flood of faulty, poorly-understood models entering them market via internal and public-facing enterprise systems?
- How will these systems impact their users? Will users accept the (relative) lack of transparency offered by these systems for production workloads?
- Will Google and others develop tools that help users understand the statistical biases of their datasets? What do you think the biggest issues will be?
If you made it this far, I’d be very interested in hearing your thoughts on the above, so please don’t hesitate to reply!
In any case, what’s clear and most exciting here is that powerful tools and technologies are rapidly becoming more accessible, and this will have a huge impact on how, and how quickly, machine learning and AI are adopted across many industries.