
Get ready to delve into newsletter number twelve!
De-mist-ifying AI and the Cloud
The other day my friends Aaron Delp and Brian Gracely interviewed me for their cloud computing podcast, The CloudCast. I’ve been spending a lot of time of late thinking about the multi-faceted relationship between machine learning, AI and the cloud of late, for some upcoming research on the topic, and our discussion provided a nice opportunity to summarize some of my thoughts on the topic. (The podcast should post to their site in a couple of weeks; I’ll keep you posted here.)
Most media coverage of cloud computing and artificial intelligence treat these two topics, for the most part, as distinct and independent technology trends. However, the two are, and will remain, inexorably tied to one another.
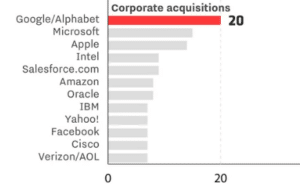
The leading cloud vendors are all investing heavily in AI. Google, Microsoft, Salesforce and Amazon represent two-thirds of the top six companies with the most AI acquisitions, according to Quid data published by Recode.
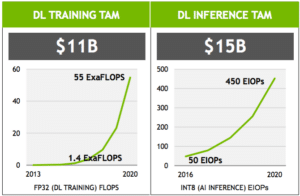
 A number of reasons are motivating these firms’ investments, not the least of which are projections that AI training and inference workloads are huge potential growth markets for cloud vendors. In a recent investor presentation, NVIDIA projected that deep learning training and inference represent $11 billion and $15 billion markets respectively, both with steep growth curves.
A number of reasons are motivating these firms’ investments, not the least of which are projections that AI training and inference workloads are huge potential growth markets for cloud vendors. In a recent investor presentation, NVIDIA projected that deep learning training and inference represent $11 billion and $15 billion markets respectively, both with steep growth curves.
Three types of cloud-based AI offerings
When I think of AI in the cloud, three distinct delivery models come to mind:
AI-optimized infrastructure.
- These are traditional cloud Infrastructure-as-a-Service (IaaS) offerings that have been optimized for machine learning and AI workloads. One obvious optimization comes in the form of GPU support, but network and memory architectures play a role here as well, as do tooling, developer experience and pricing model. Users get a lot of control and customizability over the infrastructure, but they must ultimately manage it themselves.
Cloud-based data science platforms.
- These offerings represent the next step up in terms of abstraction. Users of these platforms, typically data scientists, don’t have to think about the underlying infrastructure supporting their workloads. Rather, they get to work exclusively in the realm of higher level concepts such as code notebooks, ML models, and data flows. They trade off some control for speed and agility, and they’re not responsible for managing the underlying infrastructure.
Cloud-based AI (e.g. cognitive) APIs.
- Finally, these offerings represent the tip of the AI in the Cloud pyramid. They are simply cloud-hosted APIs backed by pre-trained models. A common example is image object detection. A developer calls the object detection API passing in an image, and the API returns an array of items that are detected in the image. These APIs make AI extremely accessible for developers who just want to build smarter apps, but you lose a lot of control. In many cases, you can’t even train the models on your own data, so if you get too far afield from the basics you may be out of luck.
I’ll be elaborating on each of these areas over the upcoming weeks, and am planning to publish a three-part “AI in the Cloud” research series that covers each in depth. Stay tuned.
Join Team TWIML!
TWIML is growing and we’re looking for an energetic and passionate Community Manager to help expand our programs. This full-time position can be remote, but if you happen to be in St. Louis, all the better. If you’re interested, please reach out for additional details.