
I recently set out to answer what seemed like a straightforward question:
If an AI agent is relying on remote frontier models and primarily doing ordinary orchestration work—calling APIs, fetching web pages, coordinating tools, and running scripts—how much hardware does the agent itself actually need?
The question came up after Qualcomm sent me a Rubik Pi 3 development board based on its latest Dragonwing processor. Like many people experimenting with agent frameworks, I’ve generally run my always-on OpenClaw workloads on cloud VPS instances. The Rubik Pi presented an opportunity to test how little hardware is actually required for this class of workload.
The experiment seemed simple enough: run the same OpenClaw tasks on both systems and compare the results.
The Rubik Pi performed admirably. But the most interesting result wasn’t the hardware performance.
It was how difficult it became to isolate hardware performance in an agentic system.
The Benchmarking Problem
Traditional software benchmarking is relatively clean. You run the same workload on different hardware and compare the results.
Agentic systems are messier. The runtime of a task depends on many layers:
- Agent behavior
- Framework design
- Tool selection
- Network interactions
- Model latency
- Hardware
During testing, I found multiple cases where the biggest source of variation wasn’t the machine itself. One run might use a browser. Another might use direct web fetches. One might perform extensive planning. Another might find a shortcut.
Those runtime choices often had a much larger impact on runtime than the difference between the VPS and the Rubik Pi.
This graphic captures how I’ve started thinking about the problem:
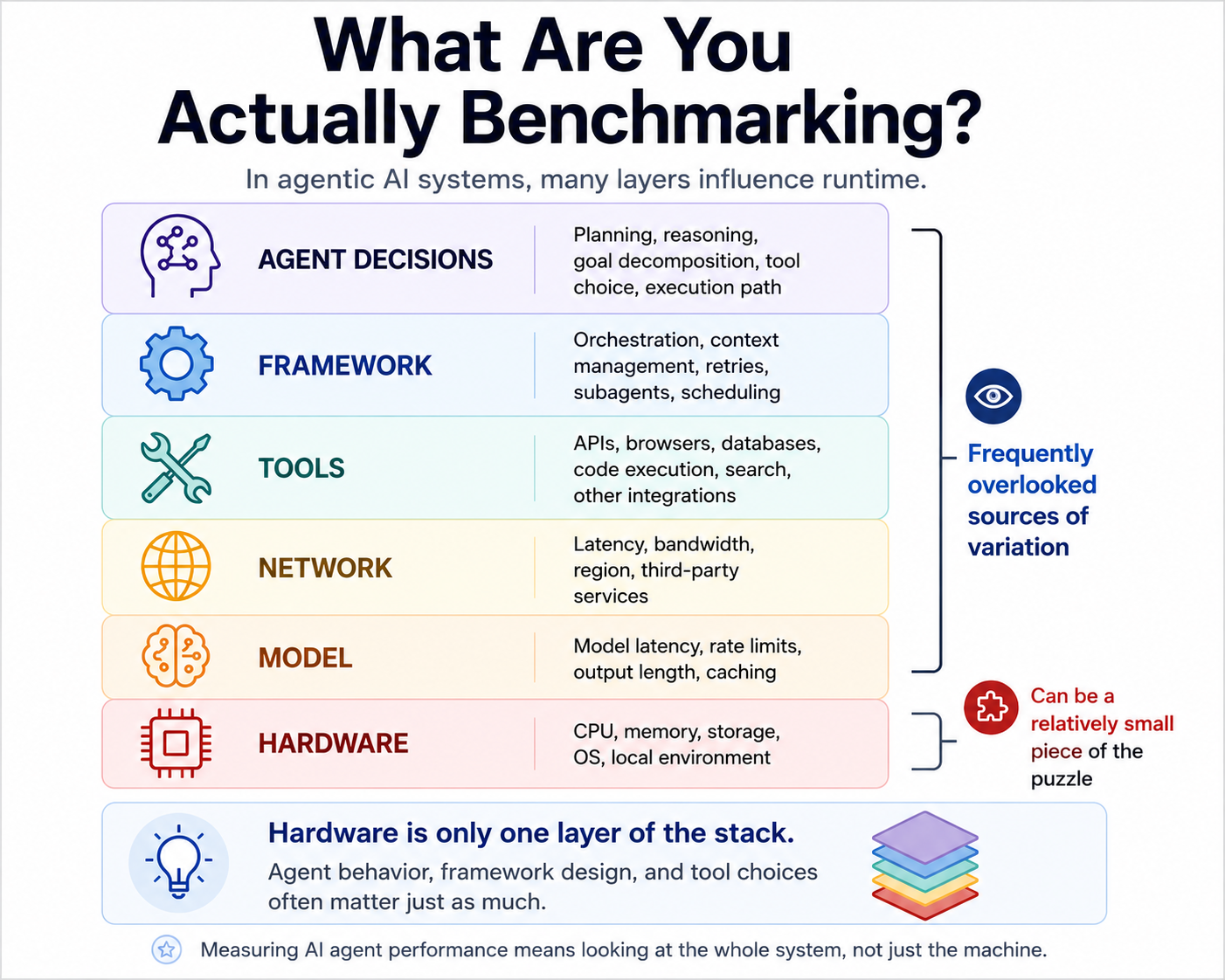
Hardware Matters. Just Not By Itself.
None of this means hardware doesn’t matter. It clearly does. The Rubik Pi and VPS were not identical.
Both were also substantially slower than running a comparable task directly in ChatGPT.
But the experiment reinforced a more important point: hardware is only one layer of the stack.
When evaluating agent systems, we’re often benchmarking:
- the model
- the framework
- the tools
- the prompts
- the network
- the hardware
all at the same time.
That makes clean conclusions much harder to draw than they first appear.
A Practical Takeaway
Despite the caveats, one conclusion did emerge. For the kinds of asynchronous agent workloads I run—scheduled research, content gathering, summarization, and automation—the Rubik Pi performed well enough that I plan to retire the VPS I’ve been using for these tasks.
That doesn’t mean I’ll be replacing ChatGPT, Claude, or Gemini on my laptop anytime soon. Interactive workflows are a different story.
But for always-on agent infrastructure performing recurring, scheduled tasks, the experiment convinced me that smaller, lower-power systems deserve more attention than they typically receive.
The most interesting question, then, may not be how fast the hardware is.
It may be whether we understand what we’re actually benchmarking in the first place.