
Stefan Lee is involved in a number of projects around emergent communication. To hear about more of them, in addition to the ViLBERT model, check out the full interview! TWiML Talk #358 with Stefan Lee.
One of the major barriers keeping robots from full immersion in our daily lives, is the reality that meaningful human interaction is dependent on the interpretation of visual and linguistic communication. Humans (and most living creatures) rely on these signals to contextualize, operate and organize our actions in relation to the world around us. Robots are extremely limited in their capacity to translate visual and linguistic inputs, which is why it remains challenging to hold smooth conversation with a robot.
Ensuring that robots and humans can understand each other sufficiently is at the center of Stefan Lee’s research. Stefan is an assistant professor at Oregon State University for the Electrical Engineering and Computer Science Department. Stefan, along with his research team, held a number of talks and presentations at NeurIPS 2019. One highlight of their recent work is the development of a model called ViLBERT (Vision and Language BERT), published in their paper, ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks.
BERT Models for Natural Language Processing
BERT (Bidirectional Encoder Representations from Transformers) is Google’s popularized model that has revolutionized natural language processing (NLP). BERT is what’s called a language model, meaning it is trained to predict the future words in a sentence based on past words. Another example is GPT-2, which caused a controversy when released by OpenAI last year.
Part of what makes them so special is that they are bidirectional, meaning they can contextualize language by reading data from both the left and right. This builds relationships between words and helps the model make more informed predictions about related words. They also pre-train models on large sets of unlabeled data using a transformer architecture, so data sequences don’t need to be processed in order, enabling parallel computations.
Models like BERT work by taking “a large language corpus and they learn certain little things to build supervision from unlabeled data. They’ll mask out a few words and have them re-predict it based on the other linguistic context, or they’ll ask if a sentence follows another sentence in text.”
Extending BERT to the Visual Domain
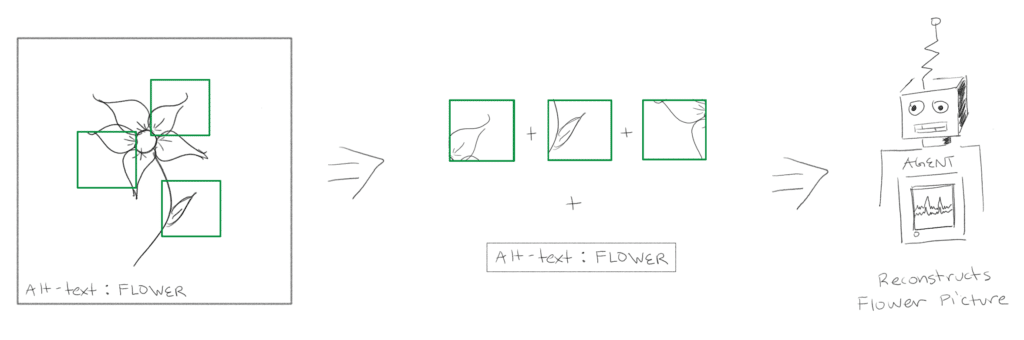
ViLBERT is an extension of the BERT technique. To apply the BERT model to vision and language, the team worked with a data set called Conceptual Captions, composed of around 3 million images paired with alt-text. Their method is to mask out random parts of the image, and then ask the model to reconstruct the rest of the image given the associated alt-text. “Likewise, we’re asking, does this sentence match with this image or not? or masking out parts of the language and having it reconstruct from the image and the text. We’re designing this self-supervised multi-model task with this large weekly supervised data source.”
Visual Grounding
Stefan describes that “Most of natural language processing is just learning based on its association with other words. Likewise on the visual side, you’re learning to represent some sparse set of classes. Those classes often relate to specific nouns, but they don’t have a sense of closeness, so there’s no idea that the feature for a cat should be close to the feature for a tiger…The point of ViLBERT is to try to learn these associations between vision and language directly. This is something we usually call visual grounding of a word.”
Humans do this naturally because we often have the inherent context to imagine a visual representation of something. For example, the words “wolf head” might bring up certain imagery of wolves, but machines lack the same visual associations. What Stephan is working towards with ViLBERT is to present the agent with something like, “red ball” and have it interpret that to reconstruct an image of a red ball.
How Vilbert Works: Bounding Boxes and Co-Attentional Transformer
In object detection, bounding boxes are used to describe the target area of the object being observed.
For the purpose of ViLBERT, an image is dissected as a set of bounding boxes that are independent of each other. Each box is given a positional encoding that shows where the box was pulled from, but ultimately the order of the sequence is not important. BERT works in the same way where you have a sequence of words (a sentence) that are treated as independent inputs and given a positional embedding. “It’s just a set. It’s an unordered set. In fact, the actual input API for BERT looks the same in our model for the visual side and the linguistic side.”
The bounding boxes are output by an R-CNN model trained on the Visual Genome. The R-CNN model “can produce quite a lot of bounding boxes and you can sample from it if you’d like to increase the randomness.” Something to note is that many of the bounding boxes are not well aligned and the data could come back as fairly noisy. “Sometimes you’ll have an object like a road…it doesn’t do a great job of honing in on specific objects.” While the model is not trained on the visuals from scratch, it still has to learn the association even when it might not be obvious.
To train the model, certain parts of the image (bounding boxes) are removed, and the model is asked about alignment between the alt-text and the image. The distinction between BERT is that “In BERT, it’s a sentence and the next sentence, and you’re predicting whether one comes after the other, but in our case, it’s an image and a sentence, and we’re asking does this align or not? Is this actually a pair from conceptual captions?”
At the end of the process, “what we get is a model that has built some representations that bridge between vision and language” which can then be fine-tuned to fit a variety of other tasks.
Applications and Limitations
Since the ViLBERT paper, the model has been applied to around a dozen different vision and language tasks. “You can pre-train this and then use it as a base to perform fairly well, fairly quickly, on a wide range of visual and language reasoning tasks.”
In addition to fine-tuning for specific task types, you can adjust for specific types of data or data language relationships.
One useful adaptation is for Visual Question and Answering (VQA) to help those who are visually impaired ask questions about the world around them, and receive descriptive answers in return. To modify the model for VQA, you could feed the questions as the text inputs and “train an output that predicts my subset of answers.” ViLBERT is pre-trained on a dataset of images and captions as the text input. For VQA, you would use the questions as the text input and have the model reconstruct answers as the output.
While ViLBERT is a solid starting point for the field, Stefan notes that the grounding component of the research is still underdeveloped. For example, if the model is trained for VQA on a limited dataset like COCO images, there may be objects that are not accounted for because the machine never learned they existed. “One example that I like to show from a recent paper is that [COCO images] don’t have any guns. If we’ve fed this caption trained on COCO with an image of a man in a red hat with a red shirt holding a shotgun, and the caption is a man in a red hat and a red shirt holding a baseball bat, because he’s wearing what looks like a baseball uniform and he’s got something in his hands. It might as well be a baseball bat. If we talk back to these potential applications of helping people with visual impairment, that kind of mistake doesn’t seem justifiable.”
Future Directions For Visual Grounding
One related area of research that Stefan has started to branch into is the interpretation of motion. The problem with images is that it can often be difficult to distinguish between active behaviors and stationary behaviors. “For a long time in the community, grounding has been on static images, but there’s actually a lot of concepts that rely on motion, that rely on interaction to ground. I could give you a photo and you could tell me it looks like people are talking, but they could just be sitting there quietly as well.” There is less emphasis on the interaction, which is a key element not only to understanding communication, but for accuracy in reading a social situation. Machines are not yet able to catch on to these distinctions and it’s a growing area of interest for Stefan.