
For more on the SLIDE algorithm check out the podcast that inspired this article—[TWIML AI Podcast #355 with Beidi Chen].
The conversation goes deeper into the team’s work on locality-sensitive hashing.
Graphics Processing Units (GPUs) have become the accepted industry standard for training deep learning models. While the raw compute power of GPUs has eclipsed that of CPUs, and is particularly effective for the matrix multiplication which abounds in deep learning training, the hardware can also be quite costly, limiting its accessibility. That’s why a recent paper by researchers at Rice University has generated quite a bit of interest… Having asked themselves, “Is GPU the only way to solve this problem?” they found a novel answer in the use of smarter training algorithms.
Beidi Chen is part of the team that developed an algorithmic, software-based approach that allows CPUs to outperform GPUs for some deep learning tasks. She presented her team’s paper, SLIDE: In Defense of Smart Algorithms Over Hardware Acceleration for Large-Scale Deep Learning Systems at MLSys: the Workshop on Systems for ML at the recent NeurIPS conference in Vancouver.
The team set out to address the bottleneck that insufficient computational power often creates for training large-scale neural networks. Their solution is an algorithm called SLIDE (Sub-Linear Deep learning Engine) which combines a few elements: Randomized Algorithms (applies randomness in its logic); Multicore Parallelism (performing several computations at the same time); and Workload Optimization (maximum performance for data processing).
Extreme Classification & Redundancy in Deep Neural Networks
For the purposes of their research, Beidi’s team focused on the problem of extreme classification, also called extreme multi-label learning. In extreme classification, the challenge is to train a classifier that can accurately determine the best subset of labels (classes) for a given datapoint from an extremely large set of labels, i.e hundred of thousands or millions of possible labels. (For context, compare this to the popular ImageNet dataset, where images are categorized into about 20,000 possible classes.)
To illustrate this problem, Beidi uses the example of searching for shoes on Amazon. Maybe you want to look for “black shoes.” To show you the right products, Amazon’s search engine needs to identify which of their many types of products you’re probably looking for.
The thing with applying deep learning to this type of problem is that the majority of the required computations are ultimately redundant or irrelevant. For example, if you’re looking for shoes, the parts of the neural network focused on distinguishing between completely different product classes, like headphones, are wasteful. “The problem is, before you do the computation, you don’t know which parts are important or which parts are not.”
The SLIDE algorithm exploits this “sparsity” characteristic of extreme classification networks. Sparsity here refers to the idea that while these neural networks may have many neurons, only a few of them are really important to predicting the class of the input.
Locality Sensitive Hashing
What Beidi and her collaborators did was turn the scenario into a search problem of sorts.
The goal is to find those neurons in the hidden layers of a neural network that matter most. In other words, the neurons with the highest activations.
To do this they rely on locality-sensitive hashing (LSH), an algorithmic technique that hashes similar input items into the same “buckets” with high probability. LSH was developed over 20 years ago to facilitate nearest neighbor search, that is identifying those query responses that are closest to queries. Mathematically, the queries and responses in nearest neighbor search are typically represented as vectors, and their similarity (how “near” they are) is defined to mean that their dot product is large. So LSH puts all of the vectors in a given search space with a high dot product into the same bucket, and allows us to retrieve the related items very quickly.
Exploiting Network Sparsity
What does all this have to do with neural networks? Well, since neuron activations are just vector dot products, given an input vector, we can use LSH and the hash tables it produces to identify the neurons that we care most about (i.e. those with high activations), instead of the typical vector multiplication step.
Since LSH can identify the important activations for an input, the SLIDE algorithm just makes the calculations necessary to evaluate those. The other activations are treated as 0 and never computed.“
Using LSH, SLIDE “predicts which computations are going to give you high density so that you just compute those, to [approximate] the full computation. In this way, all the computations in your network will be sparse,” for both the forward and backwards phases of training. This dramatically reduces the amount of compute time required to process the data and train the network.
“SLIDE has its natural advantage here because we’re only selecting, for example 1% to 5% of the active nodes for each layer, so that in the backpropagation, the gradient updates is also very sparse. For the distributed setting, this is naturally very efficient.”
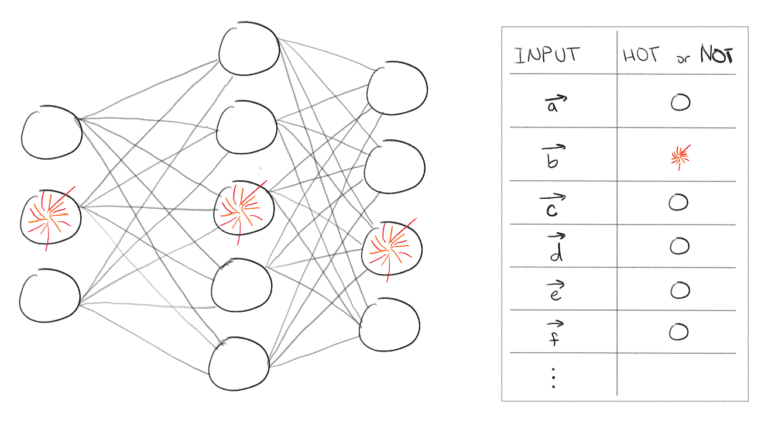
Rather than calculate all the activations in a neural network, SLIDE uses a hash table to look up the meaningful few and ignores the rest.
Evaluating on Delicious and Amazon Datasets
In their paper, Beidi’s team evaluated SLIDE on two large benchmark datasets that are commonly used in extreme classification research, Delicious-200K and Amazon-670K. The former is focused on classifying web bookmarks and the latter on product recommendations. They compare the performance and accuracy of the SLIDE algorithm running on CPUs to that of an optimized TensorFlow solution for extreme classification running on GPUs.
For this task, they showed that training with the SLIDE algorithm running on 44 CPU cores can outperform training the same network using TensorFlow running an NVIDIA V100 GPU, with no drop in accuracy.
The convergence time required is 2.7 times less than with TensorFlow GPU (one hour vs. 2.7 hours).
“With careful workload and cache optimizations and a data access pattern” they “further speed up SLIDE by roughly 1.3 times, making the overall speed up to 3.5 times faster than TF-GPU and over 10x faster than TF-CPU.”
Limitations
At this point, SLIDE has only been applied and tested for the case of extreme classification, which is based on fully-connected neural networks. While the approach may also be useful for other types of networks, such as the convolutional neural networks (CNNs) community used in computer vision application, and the LSTM networks often used in natural language processing (NLP) use cases. The team hopes to extend SLIDE to include convolutional layers as a next step.
“For another line of work, we were thinking about the distributed, because it’s well known that for the distributed setting the computational bottleneck is the communication.”
Beidi also hopes the technology can eventually be applied to GPU environments. The main limitation thus far is the high memory requirements of maintaining the hash tables, but recent work into dynamic hash tables being performed at UC Davis holds hope that it might be possible to implement LSH on GPUs.
Since publishing their work, numerous organizations have reached out with interest. Namely, the team has worked closely with Intel to refine the framework with the goal of including SLIDE in future deep learning libraries.