
Getting to know Andrea Banino
Andrea’s background as a neuroscientist informed his work in deep learning. At DeepMind, Andrea’s research falls in the realm of Artificial General Intelligence, specifically memory, along with investigating ways to shape deep learning systems so they better mimic the human brain.
“I think for us, we have a different sort of memory. We have very long-term memory, we have short-term memory. I argue that agents should be equipped with these sort of different timescale memory.”
Introduction to Human and Machine Memory
Human memory can be broadly categorized into two kinds: short-term, sometimes called “working” memory, and long-term memory.
Working memory deals with immediate phenomena and manipulates it for other cognitive functions. Tasks like counting, drawing a still life, or putting together a puzzle, where you use recently encountered information to accomplish a goal involve working memory. Recurrent neural networks and LSTMs are working memory equivalent models which hold information “online” to solve a problem, and then usually let it go afterwards.
Long-term memory can be further subdivided into episodic and semantic memory. Episodic memory, also called autobiographical memory, catalogues personal experiences and stores them in memories. This differs from semantic memory, which generally stores knowledge and concepts.
For example, knowing what a bike looks like and what it does is semantic memory, while remembering a specific bike ride with a friend is stored in autobiographical memory.
Andrea’s research background is in long-term episodic memory. There isn’t a really good long-term memory equivalent in ML models yet, but Andrea and his team have experimented with a few different arrangements.
Long-Term Memory Models
One interesting model Andrea explored is a memory-augmented neural network. This is a neural network connected to an external memory source, which allows it to write previous computations and reuse previous computation procedures when it encounters similar problems.
Retrieval augmented models are another long-term memory equivalent that have the ability to look things up in their memory. However, unlike human minds, they don’t update or reconsolidate their memory based on new information; it’s just a constant cycle of check and replicate.
Transformer models also seem promising as a substrate for long-term memory. However, Andrea notes that they have only been used to model language so far, so still limited data.
One downside is that transformers are computation-heavy and difficult to scale, so it’s definitely an open area of research.
Overfitting, in models and humans
A common critique of deep learning models is that they have a tendency to overfit to their data set, and have difficulty generalizing as a result. While this is certainly an issue, Andrea brought up another really interesting point.
Humans also memorialize, and there’s always the potential for overfitting as a person. One way evolution has helped prevent against that is by increasing the data set over time, as the set of human experiences our brains pull from increases as we age. Andrea mentioned that even humans are limited in our generalizability — limited by the data we take in.
The link between memory and learning is that consistent experience enables generalization, so people take memories and use them to predict the future. In some ways, our brains aim to minimize uncertainty, and incorporating previously-known information about the environment helps us predict what’s going to happen in the future.
Neural Network Navigation Task
In 2018, Andrea and his colleagues published a paper that explored agent navigation via representation. The model they built was programmed to mimic the human hippocampus. To understand what this model looked like, Andrea explained the three types of cells in the hippocampus that work together for spatial analysis.
Head direction cells fire when a person is facing a specific direction relative to their environment. Place cells on the other hand fire in a specific place, such as the town square or even one’s own bedroom. Grid cells fire in a hexagonal lattice format and are theorized to be the cells that allow us to calculate shortcuts.
Andrea et al. trained a neural network with models that mimicked each of these three traits. Via experimentation, using methods like dropout and introducing noise, Andrea and his team were able to determine that all three artificial cell types were necessary for successful shortcut navigation.
“We managed to make the representation emerge in our neural network, trained it to do path integration, a navigation task. And we proved that that was the only agent able to take a shortcut. So, it was an empirical paper to prove what the grid cells are for.”
Ponder Net: an algorithm that prioritizes complexity
Andrea’s most recent development is an algorithm called Ponder Net. As a general rule, the amount of computational power required for a neural network to make an inference increases as the size of a model’s input (like its feature dimensionality) increases, while the required computational power has no necessary relation to the complexity of a particular problem or prediction. By contrast, the amount of time it takes a human to solve a problem is directly related to the problem’s complexity.
Ponder Net attempts to create neural networks that budget computational resources based on problem complexity. It does so with the introduction of a halting algorithm which helps to conserve inference time, so if the computer is confident about the solution, it can stop calculating early.
How does it work? Pondering steps & the halting algorithm
Ponder Net is based on previous work called adaptive computation time. Adaptive computation time (ACT) minimizes the number of pondering steps with a halting algorithm. In ACT, the algorithm finds a weighted average of the prediction, instead of a specific prediction.
With Ponder Net, the probability of halting is found for each time step in the sequence. Andrea explained that the probability of halting is a Bernoulli random variable (think coin flip) which tells you the probability of halting at the current step, given that you have not halted at the previous step.
From there, Ponder Net calculates a probability distribution by multiplying the probability at each time step in order to form a proper geometric distribution. Once we have that, the algorithm can then calculate the loss for each prediction in the sequence that we made. The loss can then be weighted by the probability where we altered that particular step.
Andrea sees Ponder Net as a technique that can be applied in many different architectures, and he tested it on a number of different tasks. The team reported above state-of-the art performance, and that Ponder Net was able to succeed at extrapolation tests where traditional neural networks fail.
Transformers & Reinforcement Learning
Another project Andrea mentioned was a BERT-inspired combined transformer and LSTM algorithm he published in a recent paper. While LSTMs work great for reinforcement learning tasks, they do suffer from a recency bias which makes them less suited to long-term memory problems. Transformers perform better over a long string of information, however their reward system is more complicated and they have noisier gradients.
Andrea’s algorithm applied a BERT masking training to features from a CNN which were then reconstructed.
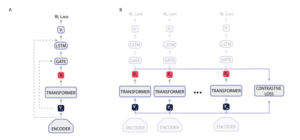
Figure 1 from CoBERL paper
Combining the LSTM with a transformer reduced the size and increased the speed of the algorithm. Something clever Andrea did was letting the agent choose whether to use the LSTM alone or to combine with the transformer
“I think there’s lots of stuff we can do to improve transformers and memory in general, in reinforcement learning, especially in relation to the length of the context that we can process.”